Раптові повені є одними з найсмертоносніших погодних явищ у світі, щороку вбиваючи понад 5000 людей. Вони також належать до найважчих для прогнозування. Але Google вважає, що несподівано розв’язав цю проблему — читаючи новини.
Хоча людство зібрало багато метеоданих, раптові повені є надто короткотривалими та локальними, щоб їх можна було виміряти всеосяжно, як, наприклад, температуру чи навіть рівень річок, які відстежуються з часом. Ця прогалина в даних означає, що моделі глибокого навчання, які дедалі краще прогнозують погоду, не здатні передбачати раптові повені.
Щоб розв’язати цю проблему, дослідники Google використали Gemini — велику мовну модель Google — для опрацювання 5 мільйонів новинних статей з усього світу, виокремивши повідомлення про 2,6 мільйона різних повеней і перетворивши ці звіти на геопросторовий часовий ряд під назвою «Groundsource». Це вперше компанія використовує мовні моделі для такого роду робіт, за словами Гіли Лойке, менеджерки продуктів Google Research. Дослідження та набір даних були оприлюднені в четвер вранці.
Використовуючи Groundsource як реалістичний базовий рівень, дослідники навчили модель, побудовану на основі нейронної мережі з довгою короткочасною пам’яттю (LSTM), споживати глобальні прогнози погоди та генерувати ймовірність раптових повеней у заданій місцевості.
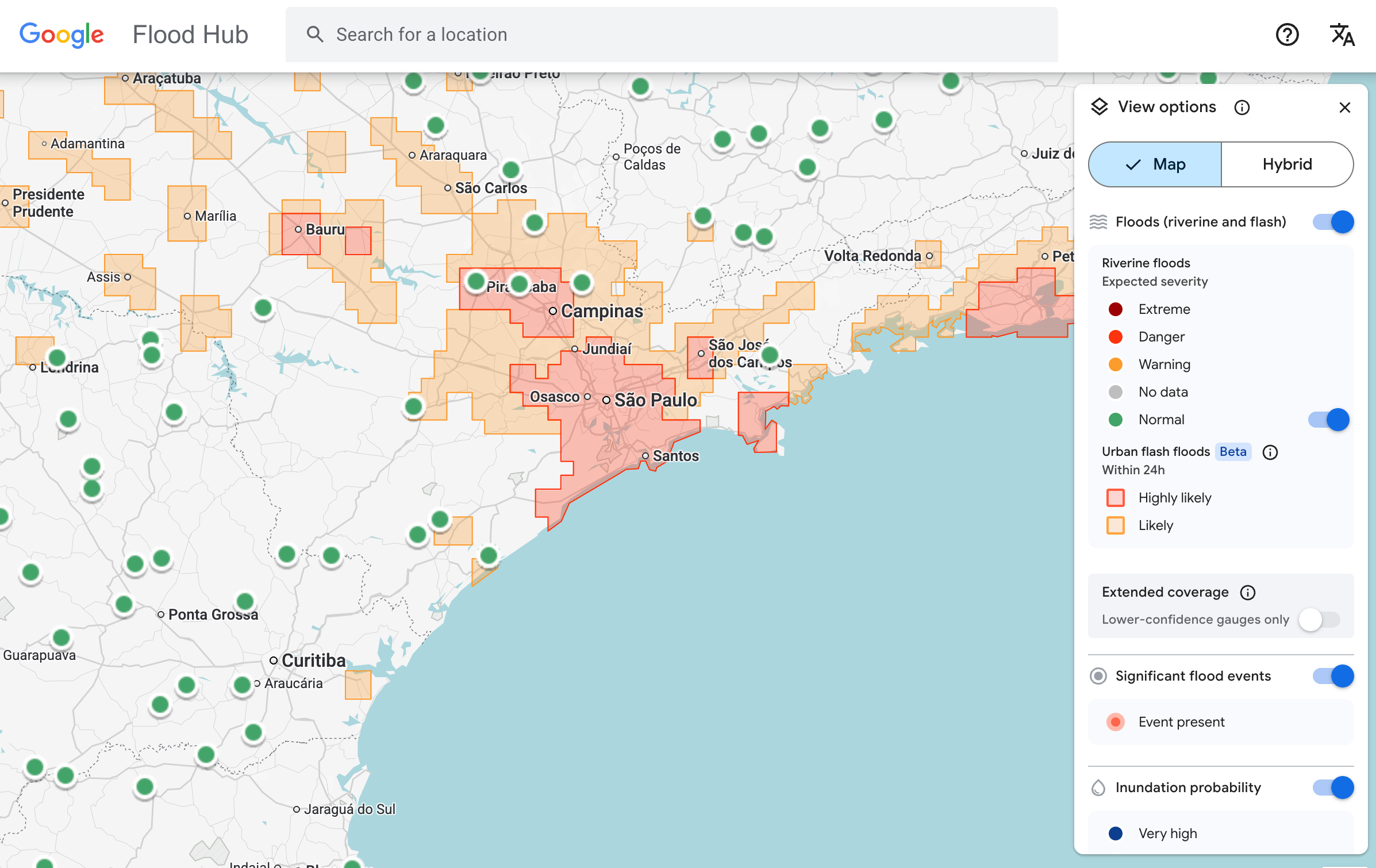
Модель прогнозування раптових повеней від Google тепер висвітлює ризики для міських районів у 150 країнах на платформі Flood Hub компанії та ділиться своїми даними з агенціями з надзвичайних ситуацій по всьому світу. Антоніо Жозе Белеза, офіцер із реагування на надзвичайні ситуації в Південноафриканській спільноті розвитку, який випробував модель прогнозування разом із Google, сказав, що вона допомогла його організації швидше реагувати на повені.
Модель все ще має обмеження. По-перше, вона має досить низьку роздільну здатність, визначаючи ризик на територіях площею 20 квадратних кілометрів. І вона не така точна, як система попередження про повені Національної метеорологічної служби США, частково тому, що модель Google не враховує локальні радарні дані, які дають змогу відстежувати опади в реальному часі.
Втім, частково сенс у тому, що проєкт був розроблений для роботи в місцях, де місцеві уряди не можуть дозволити собі інвестувати в дорогу метеорологічну інфраструктуру або не мають великих обсягів метеоданих.
«Оскільки ми агрегуємо мільйони звітів, набір даних Groundsource фактично допомагає перебалансувати карту», — розповіла журналістам цього тижня Джульєт Ротенберг, менеджерка програм команди Resilience в Google. «Це дає нам змогу екстраполювати на інші регіони, де не так багато інформації».
Ротенберг сказала, що команда сподівається, що використання великих мовних моделей для створення кількісних наборів даних із письмових якісних джерел може бути застосовано до зусиль із побудови наборів даних про інші ефемерні, але важливі для прогнозування явища, як-от хвилі тепла та зсуви ґрунту.
Маршалл Мутено, генеральний директор Upstream Tech — компанії, що використовує подібні моделі глибокого навчання для прогнозування рівня річок для клієнтів, зокрема гідроенергетичних компаній, — сказав, що внесок Google є частиною зростаючих зусиль зі збору даних для моделей прогнозування погоди на основі глибокого навчання. Мутено співзаснував dynamical.org — групу, яка курує колекцію метеоданих, готових для машинного навчання, для дослідників і стартапів.
«Дефіцит даних — одна з найскладніших проблем у геофізиці», — сказав Мутено. «Водночас даних про Землю надто багато, але коли ви хочете оцінити їх відповідність реальності, їх недостатньо. Це був дуже креативний підхід до отримання цих даних».
Залишити відповідь
Щоб відправити коментар вам необхідно авторизуватись.